La fouille de texte, ou la simple manipulation de fichiers textes ou de tableurs nécessite parfois des recherches complexes et des transformations de séquences de caractères que ne permettent pas les outils de base comme les fonctions (concaténation, etc.) ou le rechercher / remplacer standard. Il est alors nécessaire de passer au niveau supérieur en utilisant les expressions rationnelles (on les appelle aussi expressions régulières, ou regex, prononcer “redjex”).
Qu’est-ce qu’une regex ?
Une regex est un motif (pattern) qui va permettre de rechercher n’importe quel symbole ou chaîne de caractères, en lui attribuant un certain nombre de paramètres comme sa position dans la chaîne (string), son itération, sa portée, etc.
Où les utiliser
On peut manipuler des regex dans au moins deux outils assez communs. Elles sont disponibles (case à cocher dans “autres options”) dans le rechercher/remplacer de LibreOffice (chez Microsoft dans les anciennes versions la syntaxe est plutôt “maison”, je crois que ça s’arrange si vous avez plus récent que 2003 pour Excel et 2007 pour Word, moi c’est ce que je subis au boulot, mais je triche) et l’on peut aussi les utiliser dans la plupart des outils de renommage de masse comme KRename pour Linux et Microsoft.
Mais elles sont aussi très utiles dans Oxygen (éditeur XML) car elles entrent en jeu non seulement pour la recherche dans les fichiers, mais aussi pour l’écriture de feuilles de styles en XSLT ou pour la création de schémas XML ou de DTD (où les motifs servent à la transformation, à la capture ou à la validation de portions de texte).
On peut bien sûr les utiliser en ligne de commande dans le terminal (commande grep sur Mac et Linux) pour lancer des rechercher/remplacer sur de grands nombres de documents ou récupérer des liens internet dans des fichiers HTML. Elles sont aussi utiles pour travailler sur des bases de données MySql ou autres.
Mais le domaine où elles sont le plus répandues reste la programmation, dans tous les langages. Aussi la syntaxe peut varier suivant dans lequel on les utilise.
Les syntaxes
Il y a au moins deux types de bibliothèques (libraries) regex, avec des syntaxes et des fonctions légèrement différentes ; Posix et PCRE (Perl Compatible Regular Expression) qui est la syntaxe en Perl, aujourd’hui utilisée dans beaucoup d’outils ou de langages de programmation (c’est une bibliothèque open source). Car chaque langage (ou logiciel) recourant à des regex aura ses propres commandes, sans que la syntaxe ne varie finalement beaucoup. Mais laissons de côté ces arguties de programmeur, pour l’utilisateur, une bonne documentation suffit. Revenons à la syntaxe des expressions rationnelles telle qu’on les exploitera assez couramment dans divers logiciels.
Comment ça marche ?
Les expressions s’écrivent à l’aide de littéraux (“ce que je cherche”) et de caractères à valeurs symboliques (des paramètres qui viennent affiner la recherche), le tout constituant le motif (pattern).
Liste des principaux symboles
En regex les principaux symboles sont des métacaractères (wild card).
| symbole | signification | exemple |
|---|---|---|
^ |
représente le début (d’une ligne, d’une chaîne de caractères) | |
$ |
représente la fin (d’une ligne, d’une chaîne de caractères) | |
. |
n’importe quel caractère sauf retour à la ligne | |
* |
matche 0 ou plusieurs fois | e* représente soit “” ou “e” ou “ee” ou “eee” |
+ |
représente 1 ou plus occurrences de e | e+ représente soit “e”,”ee”,”eee”, etc |
? |
représente 0 ou 1 occurrence | s? dans villes? qui représente l’ensemble { “ville” , “villes” } |
() |
groupement, mémorisation d’une instance | le groupage est aussi utile pour faire des substitutions. |
{} |
répétition | a{2} renvoi aa |
[] |
classe de caractère | un de caractères dans la liste doit être dans la cible représentée, [A-Za-z] représente toutes les lettres. |
[^] |
classe complémentée | aucun de caractères dans la liste ne doit être dans la cible représentée, [^A-Za-z] recherche un motif sans les lettres. |
Échappement et choix
- dans une
classe[ .?*]un métacaractère est traité de manière littérale, ici on cherchera bien un point, un point d’interrogation et une étoile. - hors d’une
classeles caractères opérants s’échappent\si on veut leur attribuer leur valeur littérale dans un motif. - le choix dans un
motifs’exprime par un pipe|.
Récapitulatif détaillé des symboles
-
Une
classedésigne un ensemble de caractères :motifentre crochet[ab](ne renvoie pas une séquence, mais bien tous les caractères trouvés un à un) :[ a-z0-9]classerenvoyant toutes les lettres et chiffres ;[^ a-z0-9]classe complémentéerenvoyant tout ce qui n’est pas une lettre ou un chiffre : on la crée avec (^) en début declasse;- pour rechercher un
littéral, on l’écrit sans crochetbr[u]nrenverrabrunetbrin.
-
des
quantificateurs:+*?:*: 0, 1 ou plusieurs occurrences ;+: 1 ou plusieurs occurrences ;?: 0 ou 1 occurrence.
-
des
intervalles de reconnaissance:a{2}renvoi aa ;a{2,}renvoi aa, aaa, aaaa… ;a{2,5}renvoi aa, aaa, aaaa, aaaaa.
-
des
prédicats(ouassertions simplesfixant une condition) :^lemotifest en début de chaîne ;$lemotifest en fin de chaîne.
Les lettres échappées à valeur symbolique
En plus des symboles, on utilise des lettres échappées pour capturer en particulier des phénomènes de structuration du texte.
| symbole | description |
|---|---|
\b |
limites d’un mot. |
\t |
tabulation horizontale. |
\n |
saut de ligne. |
\v |
tabulation verticale. |
\f |
saut de page. |
\r |
retour chariot. |
\b |
fin de mot |
\s |
espace |
\S |
tout sauf espace |
\w |
tous caractères alphanumériques non accentués (inclus le tiret de soulignement _) |
\W |
tout sauf caractères alphanumériques (espace, ponctuation) |
Les options
Dans les différents langages de programmation ou les outils dédiés aux regex, un drapeau (flag) peut être ajouté au motif en guise d’option. Elles peuvent être cumulées.
ipour “insensitive” indique que le motif est insensible à la casse ;Upour le mode “Ungreedy” (non gourmand) pour indiquer que la regex doit s’arrêter après la première occurrence rencontrée ;gpour “global”, la recherche renvoie tous les résultats trouvés ;mpour “multiligne” le recherche ne s’arrête pas en fin de ligne (string).
En quoi est-ce utile ?
Je vais essayer de donner quelques exemples concrets de l’utilisation de regex.
Que ce soit pour le nettoyage de textes issus d’un OCR (depuis Gallica par exemple) ou pour construire de fichiers de métadonnées à partir des fichiers de récolement ou de catalogage sous forme de tableur, les regex peuvent vous aider.
Dans tous les cas, en fonction de l’outil utilisé, il vous faudra peut-être tâtonner pour trouver la meilleure formule (par exemple l’utilisation des regex dans LibreOffice est moins puissante qu’en ligne de commande ou dans un outil spécialisé). Mais la première approche sera toujours la même : bien analyser le document pour repérer les motifs susceptibles d’être traités à la chaîne.
[^\.]$: tous les paragraphes sans point final ;\.\w{2,3}\b: cible les extensions (.et tous caractères alphanumériques en fin de ligne), on peut affiner en contraignant à trois lettres\w{2,3}(pour LibreOffice) ;-
\s$: recherche les espaces en fin de cellules (nettoyage de fichiers de récolement par exemple ) ;[:space:]$recherche les espaces en fin de cellule dans LibreOffice
-
\s${2,}: recherche les doubles (ou plus) espaces en fin de ligne ou cellules (nettoyage de fichiers de récolement ou de longs textes avant publication) ;[:space:]{2,}recherche les doubles espaces en fin de cellule dans LibreOffice
([^\s])-$\n|-\s$\n: (en ligne de commande ou outils de regex type Regex 101 uniquement) recherche tous les tirets en fin de ligne non précédés par un espace ou non précédés par un espace mais suivis d’un espace (hyphenation). Très utile pour nettoyer des textes récupérés d’un OCR, en le débarrassant des coupes de mots en fin de ligne (ajouter le groupe capturé$1signifiant “tout ce qui n’est pas un espace juste devant” dans le bloc remplacement pour reconstituer le mot entier et supprimer le saut de ligne).
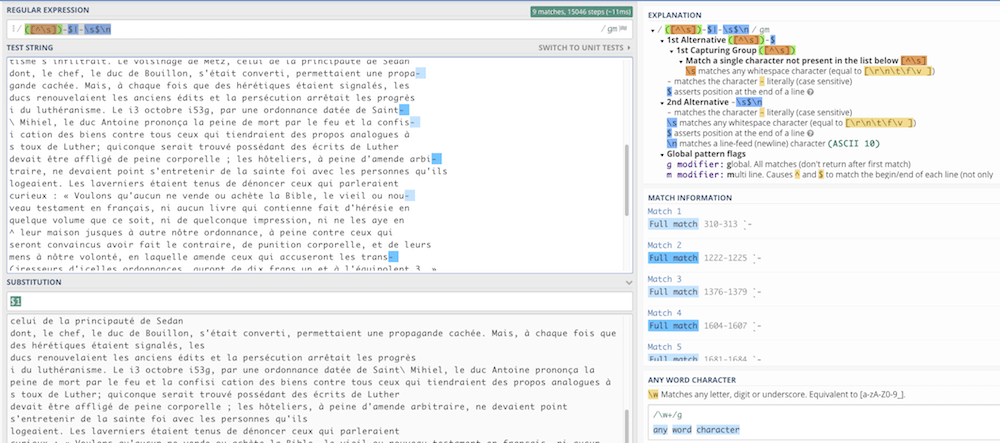
Les outils en ligne
- Regex 101 générateur de regex, avec explication des patterns, diverses syntaxes et un export du code possible (y compris avec la partie remplacement de texte) en
python,javascript,PHP. Très pratique pour apprendre et comprendre ; - RegExp tool assez complet aussi, et avec génération du code uniquement en javascript ;
- RegExr un autre testeur mais sans la possibilité d’exporter le code.
Liens utiles
- Les expressions régulières dans LibreOffice ;
- Un site très complet orienté
PHP; - En anglais, là il y a tout, c’est très dense, pour tous les langages, avec des exemples et des liens.
Les logiciels spécialisés
- RegexBuddy, testeur, constructeur de regex pour Windows, payant (30€). Cet éditeur en propose d’autres, je ne les ai pas testés.
- KRename, logiciel de renommage en masse qui a des options de regex pour Linux et Microsoft (existe en version portable).